reading-notes
https://faroukibrahim-fii.github.io/reading-notes/
Data Analysis
JupyterLab
JupyterLab is a next-generation web-based user interface for Project Jupyter.
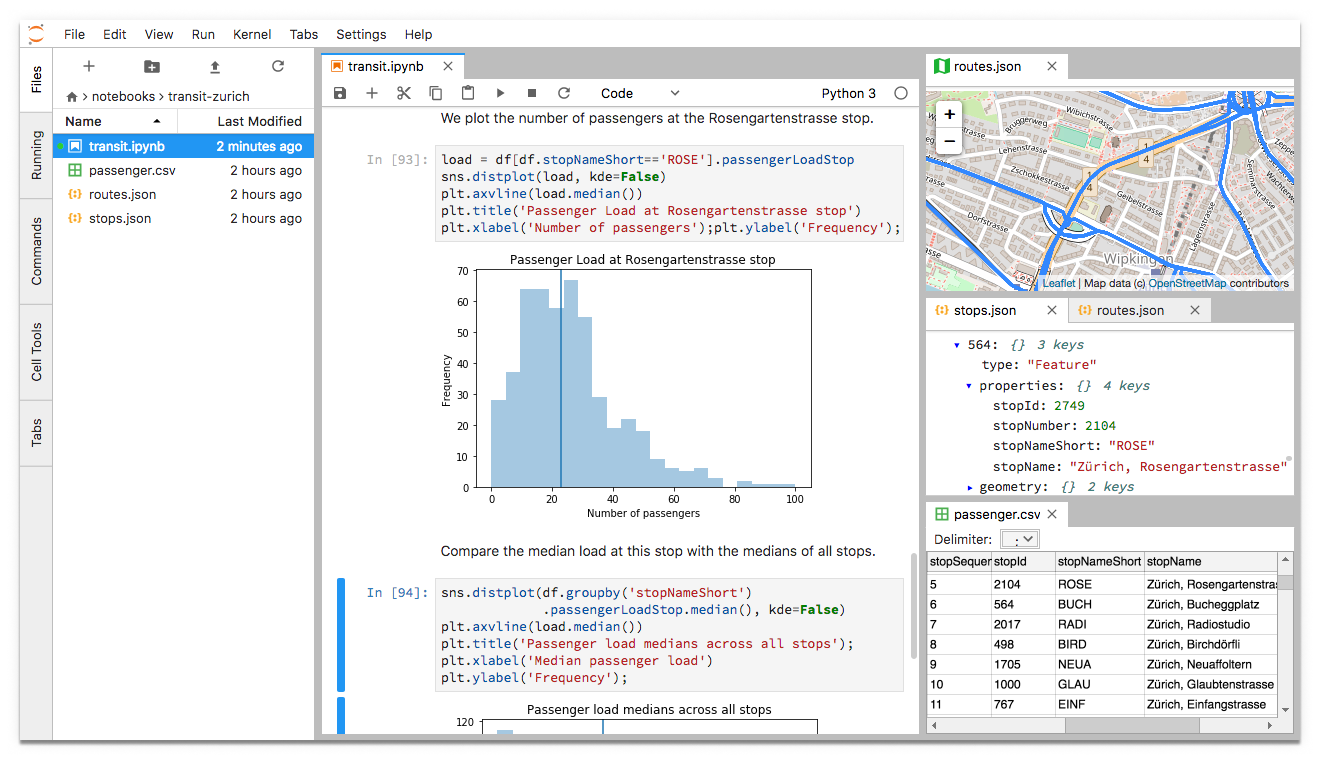
JupyterLab enables you to work with documents and activities such as Jupyter notebooks, text editors, terminals, and custom components in a flexible, integrated, and extensible manner.
You can arrange multiple documents and activities side by side in the work area using tabs and splitters.
-
Code Consoles provide transient scratchpads for running code interactively, with full support for rich output.
-
Kernel-backed documents enable code in any text file (Markdown, Python, R, LaTeX, etc.) to be run interactively in any Jupyter kernel.
-
Notebook cell outputs can be mirrored into their own tab.
-
Multiple views of documents with different editors or viewers enable live editing of documents reflected in other viewers.
JupyterLab extensions can customize or enhance any part of JupyterLab, including new themes, file editors, and custom components.
NumPy
NumPy is a commonly used Python data analysis package. By using NumPy, you can speed up your workflow, and interface with other packages in the Python ecosystem, like scikit-learn, that use NumPy under the hood.
Lists Of Lists for CSV Data
Before using NumPy, we’ll first try to work with the data using Python and the csv package.
import csv
with open('winequality-red.csv', 'r') as f:
wines = list(csv.reader(f, delimiter=';'))
The data has been read into a list of lists. Each inner list is a row from the ssv file. As you may have noticed, each item in the entire list of lists is represented as a string, which will make it harder to do computations.
As you can see from the table above, we’ve read in three rows, the first of which contains column headers. Each row after the header row represents a wine.
qualities =
[float(item[-1]) for item in wines[1:]]
sum(qualities) / len(qualities)
Numpy 2-Dimensional Arrays
With NumPy, we work with multidimensional arrays. We’ll dive into all of the possible types of multidimensional arrays later on, but for now, we’ll focus on 2-dimensional arrays. A 2-dimensional array is also known as a matrix, and is something you should be familiar with. In fact, it’s just a different way of thinking about a list of lists.
Creating A NumPy Array
We can create a NumPy array using the numpy.array function. If we pass in a list of lists, it will automatically create a NumPy array with the same number of rows and columns. Because we want all of the elements in the array to be float elements for easy computation, we’ll leave off the header row, which contains strings. One of the limitations of NumPy is that all the elements in an array have to be of the same type, so if we include the header row, all the elements in the array will be read in as strings.
import csv
with open("winequality-red.csv", 'r') as f:
wines = list(csv.reader(f, delimiter=";"))
import numpy as np
wines = np.array(wines[1:], dtype=np.float)
array([[ 7.4 , 0.7 , 0. , ..., 0.56 , 9.4 , 5. ],
[ 7.8 , 0.88 , 0. , ..., 0.68 , 9.8 , 5. ],
[ 7.8 , 0.76 , 0.04 , ..., 0.65 , 9.8 , 5. ],
...,
[ 6.3 , 0.51 , 0.13 , ..., 0.75 , 11. , 6. ],
[ 5.9 , 0.645, 0.12 , ..., 0.71 , 10.2 , 5. ],
[ 6. , 0.31 , 0.47 , ..., 0.66 , 11. , 6. ]])
Alternative NumPy Array Creation Methods
There are a variety of methods that you can use to create NumPy arrays. To start with, you can create an array where every element is zero.
Indexing NumPy Arrays
We now know how to create arrays, but unless we can retrieve results from them, there isn’t a lot we can do with NumPy. We can use array indexing to select individual elements, groups of elements, or entire rows and columns.
Slicing NumPy Arrays
If we instead want to select the first three items from the fourth column, we can do it using a colon (:).
Converting Data Types
You can use the numpy.ndarray.astype method to convert an array to a different type. The method will actually copy the array, and return a new array with the specified data type.